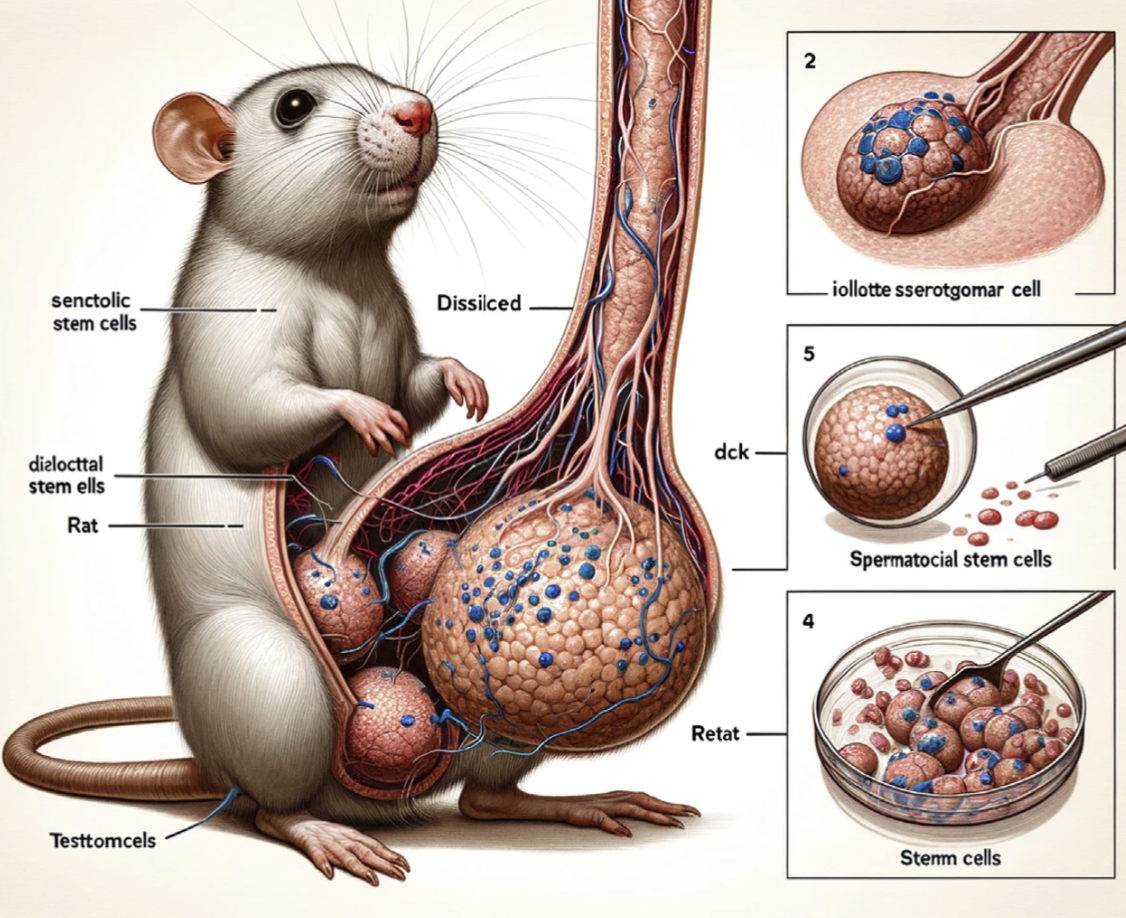
It’s the “peer-reviewed” part that should be raising eyebrows, not the AI-generated part. How the gibberish images were generated is secondary to the fact that the peer reviewers just waved the obvious nonsense through without even the most cursory inspection.
In another article, it said that one of the reviewers did being up the nonsense images, but he was just completely ignored. Which is an equally big problem.
I’ve heard some of my more senior colleagues call frontiers a scam even before this regarding editorial practices there.
It’s actually furstratingly common for some reviewer comments to be completely ignored, so it’s possible someone raised a flag and no one did anything about it.
The biggest problem with Frontiers for me is that there are some handy survey articles that are cited like 500 times. It seems that Interdisciplinary surveys are hard to publish in a traditional journal, and as a result 500 articles cited this handy overview article for readers who would need an overview.
The article I checked was in a reasonable quality, and it’s a shame I can’t cite it just because it’s in Frontiers.
Some of the reviewers have explained it as the software they use doesn’t even load up the images. So unless the picture is a cited figure, it might not get reviewed directly.
I can kindof understand how something like this could happen. It’s like doing code reviews at work. Even if the logical bug is obvious once the code is running, it might still be very difficult to spot when simply reviewing the changed code.
We have definitely found some funny business that made it past two reviewers and the original worker, and nobody’s even using machine models to shortcut it! (even things far more visible than logical bugs)
Still, that only offers an explanation. It’s still an unacceptable thing.
Yea, “should be”, but as said, if it’s not literally directly relevant even while being in the paper, it might get skipped. Lazy? Sure. Still understandable.
A more apt coding analogy might be code reviewing unit tests. Why dig in to the unit tests if they’re passing and it seems to work already? Lazy? Yes. Though it happens far more than most non-anonymous devs would care to admit!


{kind=link}
It’s the “peer-reviewed” part that should be raising eyebrows, not the AI-generated part. How the gibberish images were generated is secondary to the fact that the peer reviewers just waved the obvious nonsense through without even the most cursory inspection.
In another article, it said that one of the reviewers did being up the nonsense images, but he was just completely ignored. Which is an equally big problem.
It’s in this article.
It’s how this publisher works. They make it insanely difficult for reviewers to reject a submission.
I’ve heard some of my more senior colleagues call frontiers a scam even before this regarding editorial practices there.
It’s actually furstratingly common for some reviewer comments to be completely ignored, so it’s possible someone raised a flag and no one did anything about it.
The biggest problem with Frontiers for me is that there are some handy survey articles that are cited like 500 times. It seems that Interdisciplinary surveys are hard to publish in a traditional journal, and as a result 500 articles cited this handy overview article for readers who would need an overview.
The article I checked was in a reasonable quality, and it’s a shame I can’t cite it just because it’s in Frontiers.
Some of the reviewers have explained it as the software they use doesn’t even load up the images. So unless the picture is a cited figure, it might not get reviewed directly.
I can kindof understand how something like this could happen. It’s like doing code reviews at work. Even if the logical bug is obvious once the code is running, it might still be very difficult to spot when simply reviewing the changed code.
We have definitely found some funny business that made it past two reviewers and the original worker, and nobody’s even using machine models to shortcut it! (even things far more visible than logical bugs)
Still, that only offers an explanation. It’s still an unacceptable thing.
Actually, figures should be checked during the reviewing process. It’s not an excuse.
Yea, “should be”, but as said, if it’s not literally directly relevant even while being in the paper, it might get skipped. Lazy? Sure. Still understandable.
A more apt coding analogy might be code reviewing unit tests. Why dig in to the unit tests if they’re passing and it seems to work already? Lazy? Yes. Though it happens far more than most non-anonymous devs would care to admit!
No, “should be” as in, it must be reviewed but can be skipped if there’s a concern like revealing the author identity in a double-blind process.