
7·
28 days agoWait he didn’t invent him? Man… I
Wait he didn’t invent him? Man… I

The attacks by Iranian backed Hamas against Israel. Sources:
https://en.m.wikipedia.org/wiki/Iranian_support_for_Hamas
Disclaimer: I’m not stating support for one group or another, but the truth is necessary for a good opinion and discussion .
Ew you should use a real OS. I use arch btw.
Found the Microsoft employee.
I know this is a joke cause it doesn’t have a color, but it’s “Guau, guau” too.
Source: I am Chilean.
I don’t have a great solution for this particular problem.
However any solution that you come up with has to be resilient enough that the nodes that execute such scenario are always available.
You don’t just want a system with high availability, you want a system that will stand the test of time. For example, it might trigger 30 or 50 years from now. You might not want to use AWS or Google or Azure or any sort of system like that. They don’t seem to keep their solutions available for that long. So you’ll need to host something yourself and make sure it’s resilient to a multitude of scenarios that might bring the “back end” down.
You’d also need to set-up some sort of test for the system to make sure it’s still running and it’ll do what you want it to. Maybe it runs every 3 months or so like a fire system drill.
Honestly the trigger can be something as simple as you hitting a button connected to your system every week with a way for it to ping and prompt you to do it you if you haven’t “reset” the counter in a timely fashion.
I would probably do something like that with a weekly cadence and a whole other week to make sure I don’t miss the reset.
You probably also want to be able to set it to different modes if you think you will be away for a while. Like a vacation mode or oh shit I’m in the hospital mode.
Additionally, I also wouldn’t be as fatalistic as sending goodbyes to everyone. I would use it more as a system to sound an alarm that I’m not okay and something has happened to me and communicate that with people who could do something about it. Like verify if I’m alive or not, or contact local authorities to post a missing persons report.
This same system of notifying could also allow closer people to me to trigger an “oh shit I’m dead mode” which would then execute whatever is in that idea of yours.
These are all situations that you would want to alert your loved ones though. And the power outage one will probably be solved faster than your switch hopefully.
If we look at this as an analog to physics and “number go up” is speed then “rate of number go up go up” is literally a jerk measure.
I believe the proper terminology is Badonkadonks
FTFY
This data needs to be normalized by speed or realistic range/day. Otherwise it’s pretty meaningless.

Me on basically any post that has incorrect information from blahaj.
Tell me you’re a Java developer without telling me you’re a Java developer.

At least what I see with this experiment/article is that is overly verbose, he takes a long time to get to the point. And then when he does his methodology shows an experiment that cannot be verified. Even when something is “subjective” we can still draw conclusions from it if we set up proper non-subjective ways of evaluating the results we see (ie. Rubrics). The fact that he doesn’t really say what leads him to say in detail what is a “terrible/v. bad/bad/good result” is a massive red flag in his method.
After seeing that, I no longer read the rest of it. Any conclusions drawn from a flawed methodology are inherently fallacies or hearsay.
If in any case it is further explained in the article and that somehow refutes what I’ve postulated later on, then I would have to say that the article is poorly written.
All this to say… I agree with you, not worth the read.
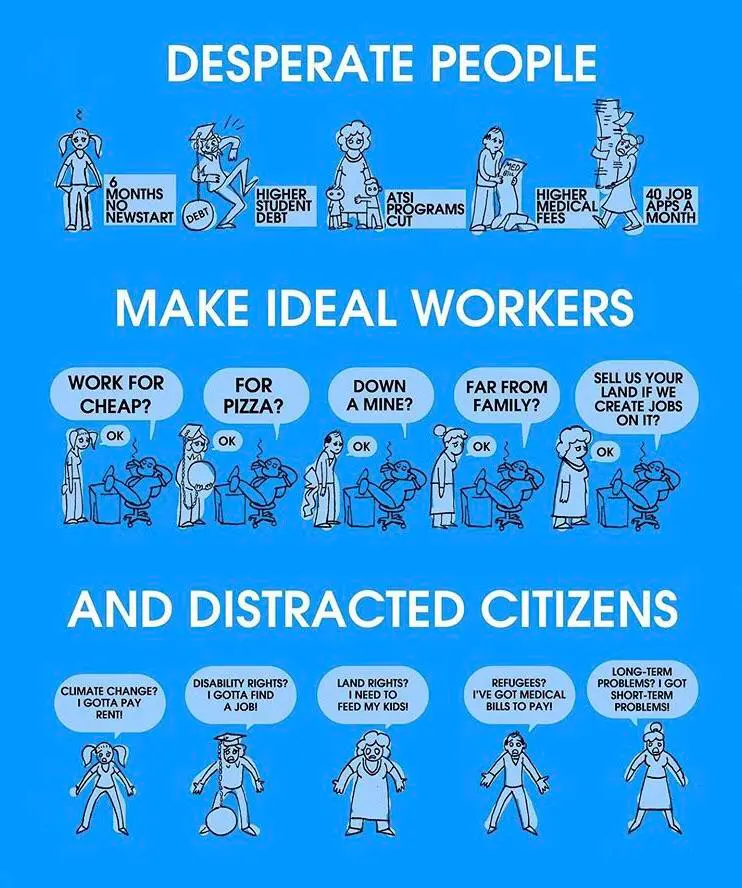
Source please?

What? Ballmer hasn’t had anything to do with msft since 2014 man.
Software engineer here, but not llm expert. I want to address one of the questions you had there.
Why doesn’t it occasionally respond with a hundred thousand word response? Many of the texts it’s trained on are longer than it’s usual responses.
An llm like chatgpt does some rudimentary level of pattern matching when it analyzes training data. So this is why it won’t generate a giant blurb of text unless you ask it to.
Let’s say for example one of its training inputs is a transcription of a conversation. That will be tagged “conversation” by a person. Then it will see that tag when analyzing hundreds of input texts that are conversations. Finally, the training algorithm writes down that “conversation” have responses of 1-2 sentences with x% likelyhood because that’s what the transcripts did. Now if another of the training sets is “best selling novels” it’ll store that “best selling novels have” responses" that are very long.
Chatgpt will probably insert a couple of tokens before your question to help it figure out what it’s supposed to respond: “respond to the user as if you are in a casual conversation”
This will make the model more likely to output small answers rather than giving you a giant wall of text. However it is still possible for the model to respond with a giant wall of text if you ask something that would contradict the original instructions. (hence why jailbreaking models is possible)







That’s the fun part about being in a place where you can hold a discussion. Some people don’t agree with you, but they can still see the benefits of the option you are talking about or even agree that they are a great solution for now.